Vingroup hoàn thành nghiên cứu giải mã gen người Việt đầu tiên
Ngày 16/12/2021, Viện Nghiên cứu Dữ liệu lớn VinBigData (Tập đoàn Vingroup) công bố đã hoàn thiện Dự án “Xây dựng cơ sở dữ liệu biến dị di truyền cho quần thể người Việt”. Với quy mô hơn 1.000 hệ gen được giải trình tự, hơn 40 triệu biến thể di truyền được phát hiện, nghiên cứu không chỉ mở ra bộ cơ sở dữ liệu quý cho cộng đồng mà còn tạo tiền đề cho sự phát triển của nghiên cứu y sinh và y học chính xác, góp phần cảnh báo điều trị sớm đến từng cá nhân người Việt trong tương lai.
Đây là bộ dữ liệu toàn hệ gen người Việt đầu tiên đảm bảo tính đại diện và phổ quát cho quần thể, phù hợp với phân bố dân cư về địa lý (miền Bắc: 37%; miền Trung 22%; miền Nam: 41%) và giới tính (cân bằng tỷ lệ nam nữ). Đặc biệt, bộ dữ liệu gen có đầy đủ chú giải về chức năng sinh học cũng như nguy cơ bệnh lý.
Dự án “Xây dựng cơ sở dữ liệu biến dị di truyền cho quần thể người Việt” đã được VinBigData khởi động từ tháng 12/2018 với sự tham gia của hơn 40 nhà khoa học gồm các chuyên gia nhiều kinh nghiệm của VinBigData, các chuyên gia tư vấn cao cấp từ các đơn vị nghiên cứu hàng đầu như Đại học Harvard, Đại học Chicago, Trung tâm Ung thư MD Anderson... cùng hàng trăm chuyên gia và tình nguyện viên Việt Nam và thế giới.

Trong 3 năm, nhóm nghiên cứu đã giải trình tự toàn bộ hệ gen của hơn 1.000 người trưởng thành khỏe mạnh, từ 35-55 tuổi, không có quan hệ huyết thống và có đủ thông tin kiểu hình và nhân khẩu học; phân tích một phần hệ gen hơn 4.000 trường hợp liên quan đến các bệnh lý phổ biến và khả năng đáp ứng thuốc. Kết quả phát hiện hơn 40 triệu biến thể di truyền, trong đó có gần 2 triệu biến thể gen phổ biến đặc trưng cho quần thể người Việt.
Quy trình phân tích dữ liệu gen và chú giải biến thể gen do VinBigData được đánh giá là tiên tiến hàng đầu thế giới. Công đoạn xử lý mẫu được triển khai tại phòng Lab đạt chuẩn quốc tế ISO 15189 (tiêu chuẩn quy định các yêu cầu về năng lực và chất lượng đối với các phòng xét nghiệm y tế) thuộc Bệnh viện Đa khoa quốc tế Vinmec. Khối lượng dữ liệu khổng lồ được xử lý bằng công nghệ hiện đại của Google, Illumina (hãng công nghệ hàng đầu thế giới về giải trình tự gen), và NVIDIA (Tập đoàn công nghệ đa quốc gia của Mỹ). Bên cạnh đó, VinBigData cũng triển khai hợp tác với khoảng 20 tổ chức nghiên cứu, bệnh viện hàng đầu trong và ngoài nước như: Đại học John Hopkins (Mỹ), The GoldenHelix Foundation (Anh Quốc), Trường Đại học Y Hà Nội, Bệnh viện Trung ương Quân đội 108…

GS.Vũ Hà Văn, Giám đốc Khoa học VinBigData (Tập đoàn Vingroup) cho biết: “Phần lớn các nghiên cứu và thực hành lâm sàng tại Việt Nam đang dựa vào cơ sở dữ liệu di truyền của các quần thể khác trên thế giới. Điều này ảnh hưởng đến kết quả của công bố khoa học cũng như chất lượng khám chữa bệnh trên người Việt. Với tiền đề là cơ sở dữ liệu biến dị di truyền dành riêng cho người Việt, VinBigData kỳ vọng sẽ mở ra hướng đi mới, góp phần phát triển y học chính xác tại Việt Nam”.
Với tổng mức đầu tư để hoàn thiện trên 4,5 triệu USD, dự án giải mã gen của Vingroup được đánh giá là có quy mô lớn nhất Việt Nam tính đến thời điểm hiện tại. VinBigData đã trở thành đơn vị tiên phong tại Việt Nam tiến hành giải trình tự toàn bộ hệ gen người Việt.
Đánh giá về ý nghĩa của nghiên cứu, GS.TS. Tạ Thành Văn, Chủ tịch Hội đồng Trường Đại học Y Hà Nội chia sẻ: “Hiện nay, các bác sĩ chủ yếu dựa vào lâm sàng, xét nghiệm sinh hóa hoặc tiền sử bệnh để thăm khám và ra quyết định điều trị. Nếu có thêm dữ liệu hệ gen, đây sẽ là một thông tin giàu giá trị, giúp gia tăng tính chính xác cũng như hiệu quả chẩn đoán, điều trị bệnh. Trên phạm vi toàn dân, cơ sở dữ liệu hệ gen người Việt được kỳ vọng sẽ là tiền đề thúc đẩy sự phát triển của y học dự phòng và thực hành y học chính xác, từ đó góp phần cải thiện sức khỏe cộng đồng”.
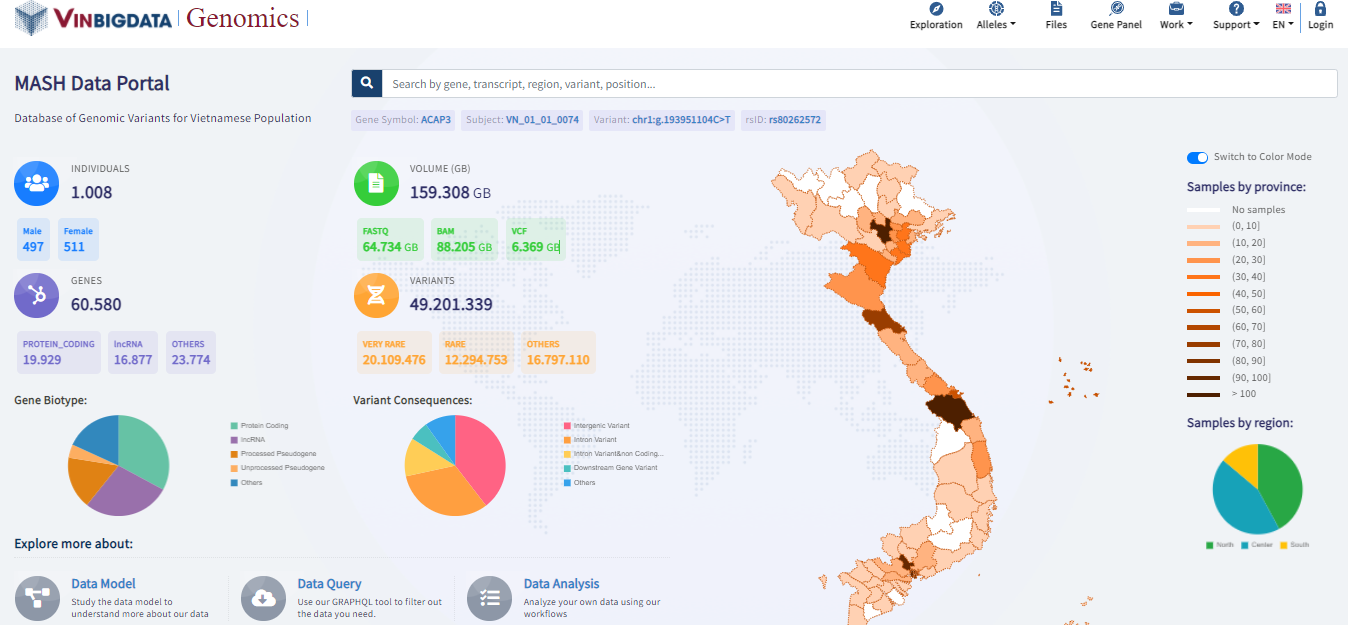
Sau khi hoàn tất, một phần dữ liệu của dự án đã được mở để cộng đồng truy cập thông qua Hệ thống quản lý, phân tích và chia sẻ dữ liệu y sinh (MASH Portal) (https://genome.vinbigdata.org). Người dùng có thể tra cứu nhằm mục đích tham khảo, phục vụ các nghiên cứu y sinh. Hệ thống cũng cung cấp thử nghiệm một số công cụ phân tích tốc độ cao (từ 30 phút đến 1 giờ) cho dữ liệu toàn hệ gen người.
Kết quả dự án sẽ được VinBigData ứng dụng trực tiếp vào các sản phẩm giải mã gen, với độ chính xác và tốc độ vượt trội, dành riêng cho người Việt. Nghiên cứu sẽ tạo tiền đề hỗ trợ khám phá đặc điểm sinh lý - tâm lý của cá nhân, cũng như dự đoán nguy cơ mắc bệnh phổ biến, bệnh di truyền lặn, đánh giá mức độ đáp ứng thuốc trong tương lai.
| Cổng dữ liệu MASH đang lưu trữ hơn 2500 Terabyte dữ liệu gen người Việt đã được chú giải, bao gồm cả dữ liệu nhân khẩu học và cận lâm sàng, phù hợp với tiêu chuẩn của Viện Y tế Quốc gia Hoa Kỳ (NIH). Truy cập hệ thống MASH HYPERLINK "https://genome.vinbigdata.org" tại đây. Trên thế giới, hiện chỉ có một số quốc gia phát triển như Hoa Kỳ, Vương quốc Anh, Pháp, Nhật Bản, Trung Quốc… mới đủ tiềm lực để giải mã trọn bộ gen người với quy mô lớn. Việc đẩy mạnh khai phá hệ gen của các quần thể được kỳ vọng sẽ góp phần thiết lập những nền tảng cơ bản về nhân chủng học, bệnh lý học, thúc đẩy y học dự phòng và điều trị cá thể hóa. |